


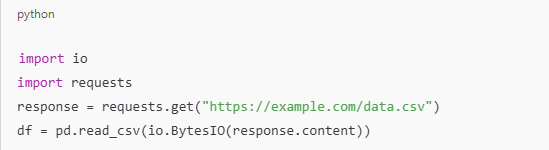
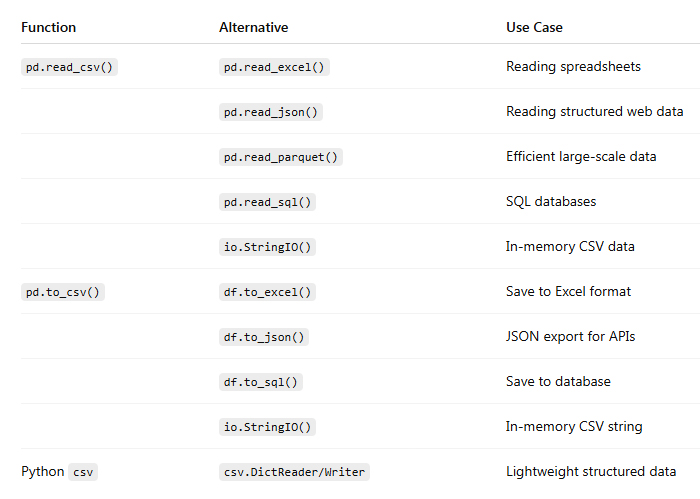
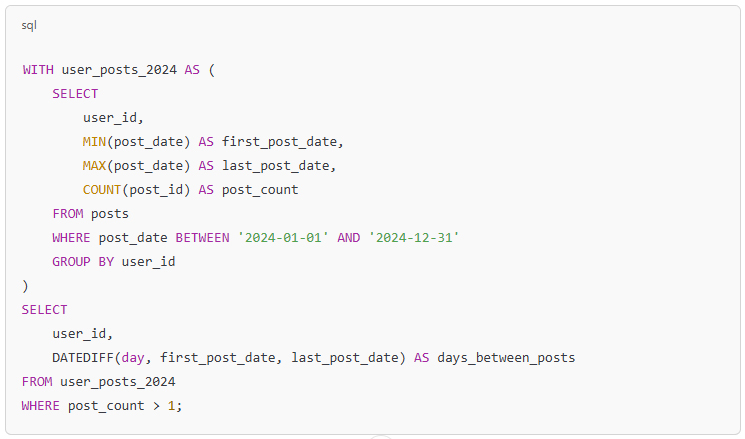
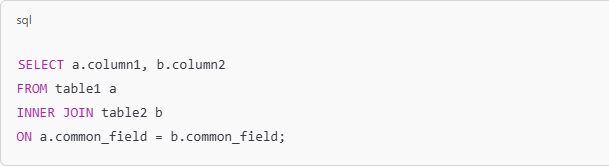
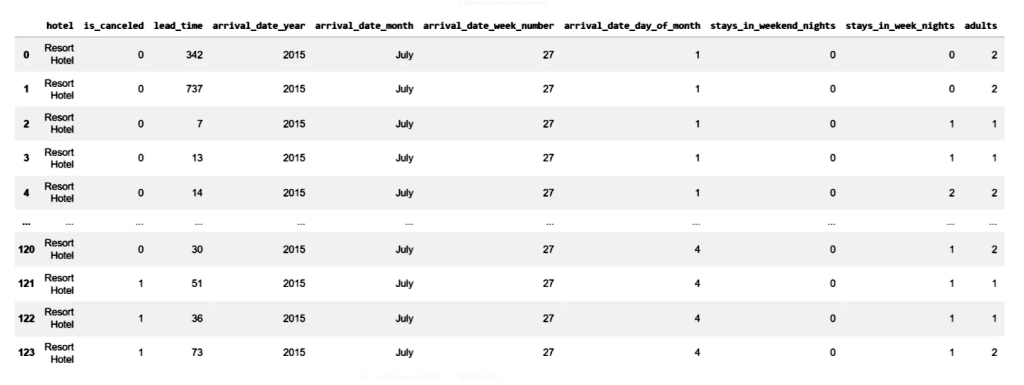
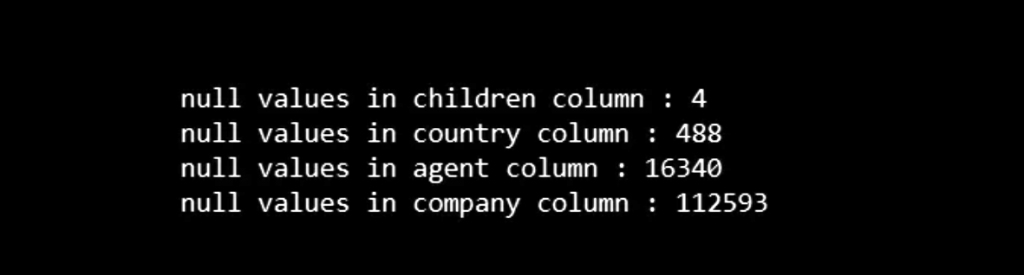
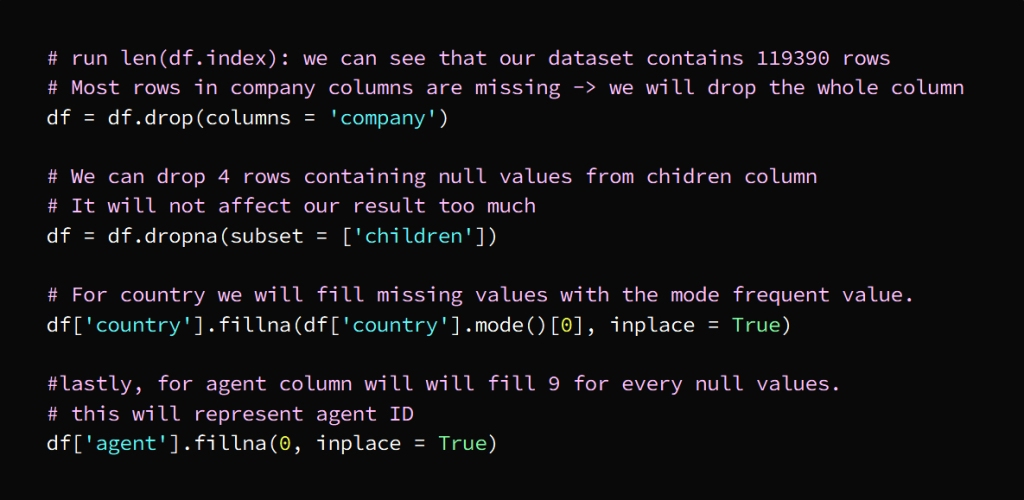
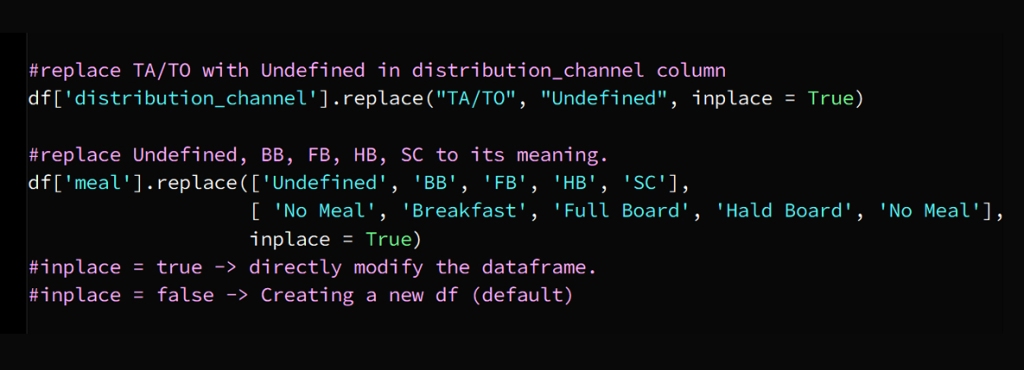
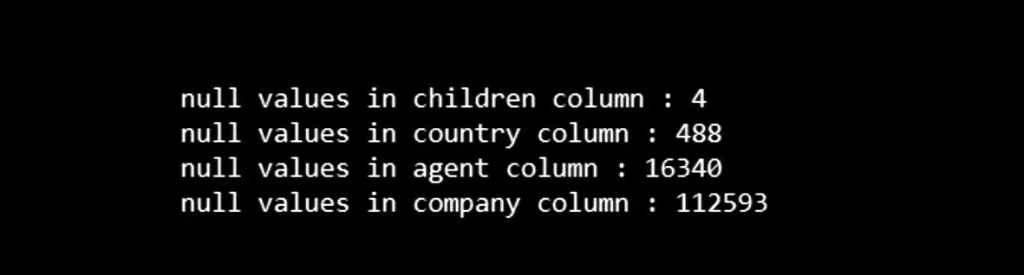
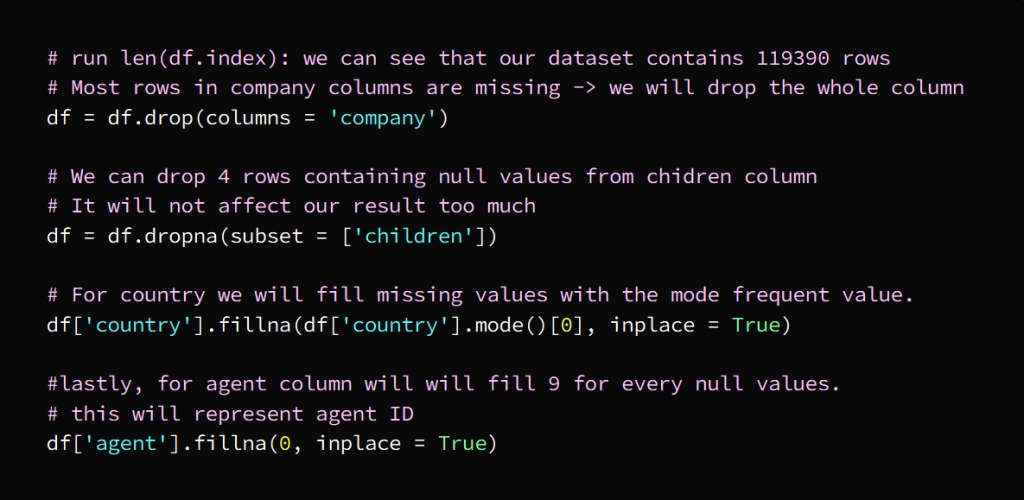
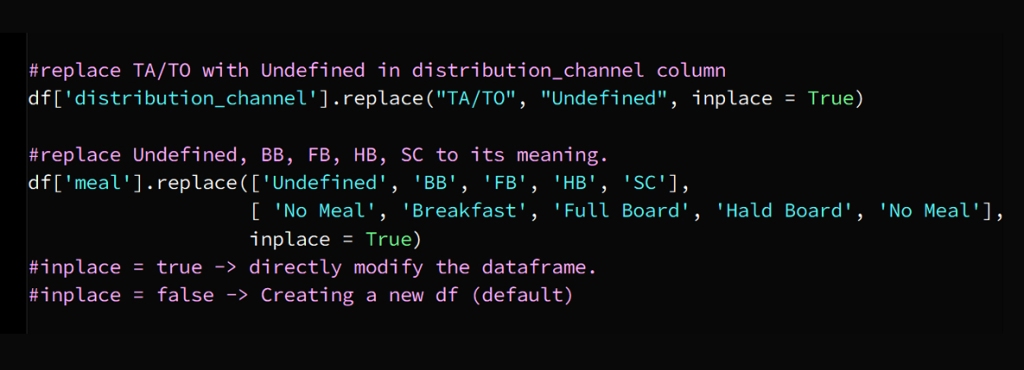
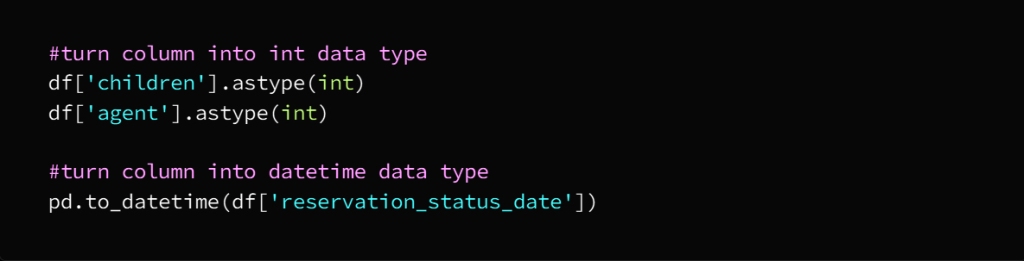
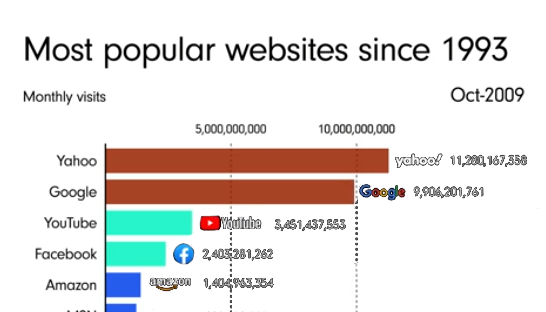
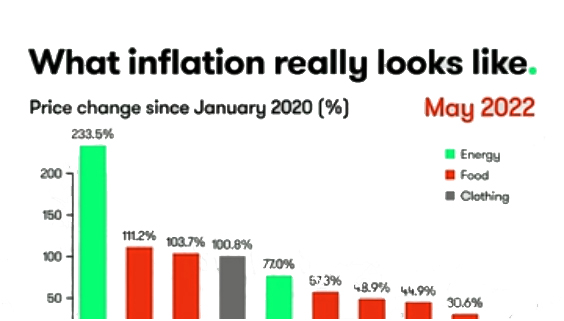
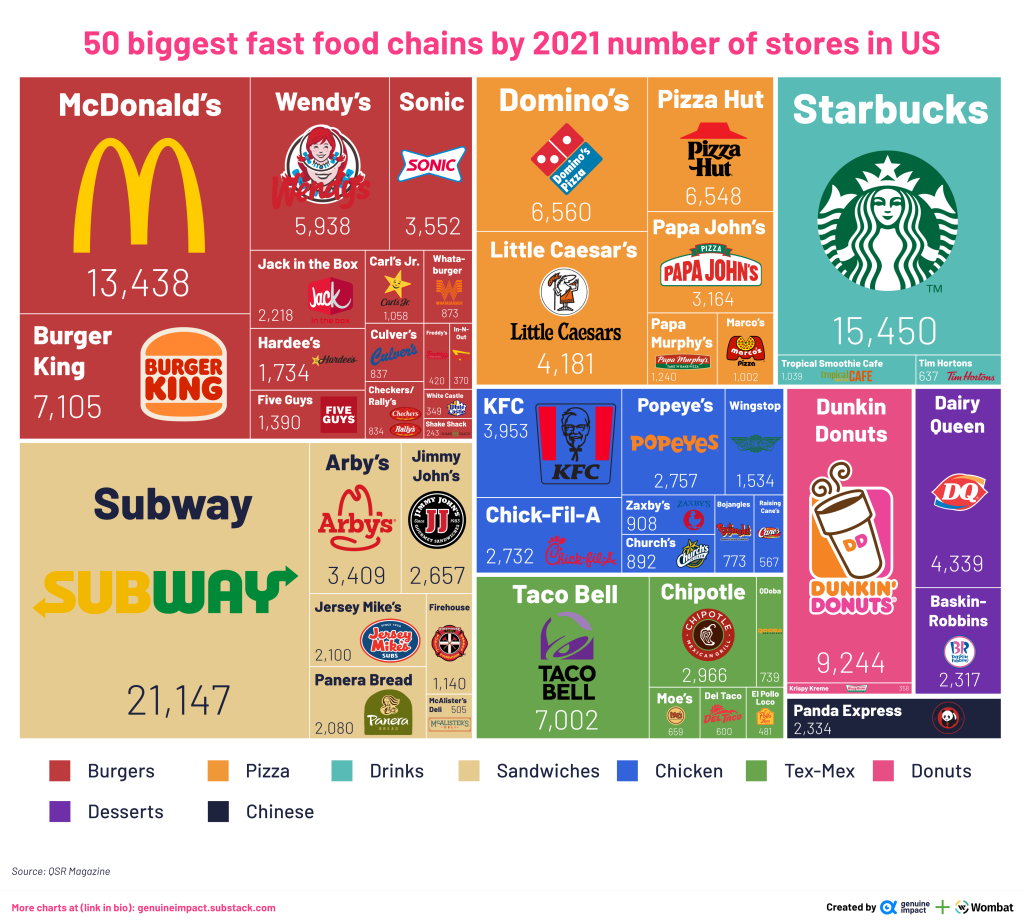
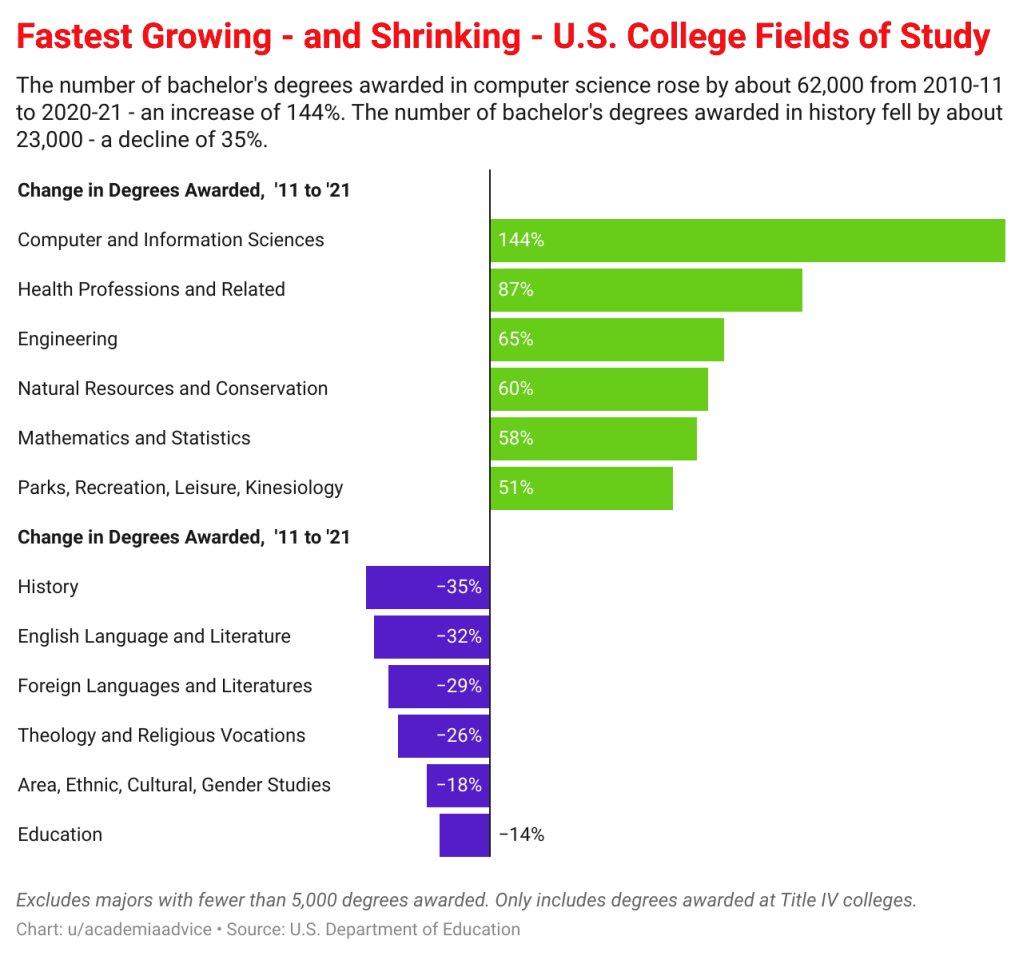
In today’s hyper-connected world, cybersecurity is more than just a buzzword; it’s a necessity. As data scientists, we deal with sensitive information on a daily basis, whether it’s user data, financial records, or intellectual property. But the ever-growing threat of data theft looms large, with hackers constantly evolving their methods and tools to gain unauthorized access to valuable information. While sophisticated cyberattacks often grab headlines, one of the most effective methods of stealing data happens through physical hacking devices. These devices are simple, easy to use, and, in many cases, nearly undetectable. In this article, we explore the eight most dangerous hacking devices that data scientists need to be aware of, shedding light on how they work and the real-world risks they pose.
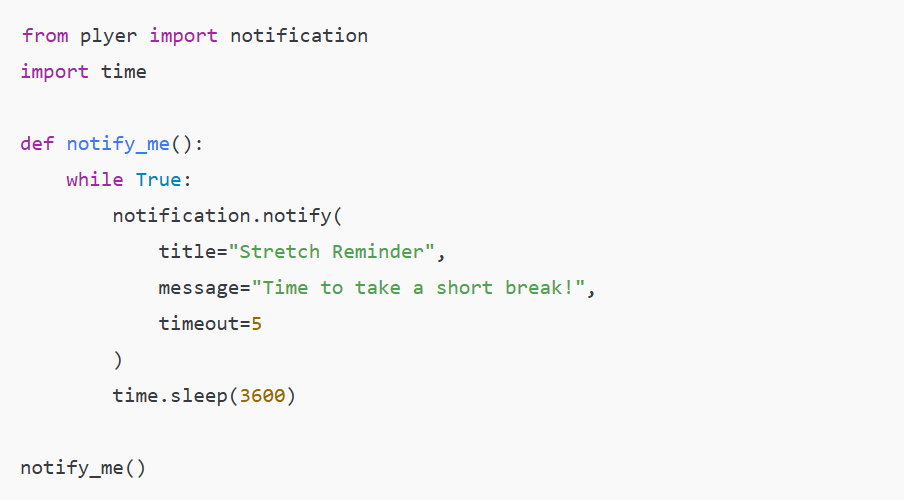
1. USB Rubber Ducky: A Small, Yet Mighty Intruder
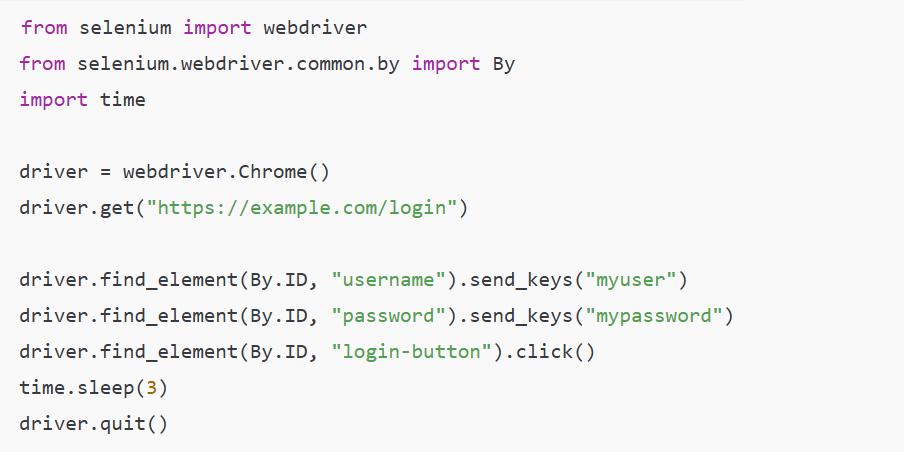
Among the most infamous hacking tools used by cybercriminals is the USB Rubber Ducky. A seemingly innocuous USB flash drive, this device is actually a high-tech keyboard emulator. When plugged into a computer, the Rubber Ducky mimics the behavior of a keyboard, sending keystrokes that can open backdoors, steal passwords, or even execute malicious code on the infected machine. Despite its relatively simple design, the Rubber Ducky’s effectiveness lies in its ability to bypass security measures like firewalls and antivirus programs by exploiting the trusted connection between a keyboard and the computer.
A real-life example of this tool being used comes from the famous 2010 attack on a United States military base in the Middle East. Hackers used a USB Rubber Ducky to infiltrate the military network and introduce a sophisticated malware called “Stuxnet,” which then went on to sabotage Iran’s nuclear program. While this case involved highly advanced malware, it illustrates just how easy it is for attackers to use small devices like the Rubber Ducky to gain control of vital systems. As data scientists, we should be aware that these devices can even be used in corporate environments to exfiltrate sensitive data from company computers.
2. Wi-Fi Pineapple: The Perfect Tool for Man-in-the-Middle Attacks
Wi-Fi Pineapple is a tool designed for penetration testing but has found its way into the hands of malicious hackers. It’s essentially a portable device that creates rogue Wi-Fi networks that unsuspecting users connect to, thinking they are legitimate hotspots. Once connected, hackers can monitor and manipulate all data transmitted between the user and the network, making it a powerful tool for executing man-in-the-middle (MITM) attacks. Wi-Fi Pineapple can intercept login credentials, banking information, and any other sensitive data being transmitted over the network.
The infamous “DigiNotar breach” in 2011 highlights the dangerous potential of MITM attacks. Hackers used a compromised digital certificate authority to conduct a series of MITM attacks, redirecting users to phishing websites that collected login credentials. In the context of a Wi-Fi Pineapple attack, a hacker could easily launch a similar attack, especially in public places like cafes, airports, and hotels where users are likely to connect to untrusted networks. For data scientists working with cloud-based or internet-of-things (IoT) data, Wi-Fi Pineapple represents a significant threat to data integrity.
3. Keylogger Devices: Stealthy and Persistent
Keylogger devices are some of the most insidious hacking tools available. These devices, which are often the size of a small USB stick or a circuit board, are designed to silently record every keystroke made on a computer or mobile device. The data collected can then be transferred to a hacker, often without the victim’s knowledge. Keyloggers can be installed on public machines, employee workstations, or even smartphones through malicious apps or physical access.
One notorious example occurred in 2005 when cybercriminals used a combination of hardware and software keyloggers to steal millions of dollars from unsuspecting victims’ bank accounts. The hackers were able to monitor keystrokes, capture usernames, passwords, and banking details, and eventually access accounts directly. As data scientists, we often rely on the security of the devices we work with to safeguard sensitive data, and the reality of keylogger attacks reminds us how easily information can be compromised through simple physical devices.
4. RATs (Remote Access Trojans): Full Control, Full Data Theft
Remote Access Trojans (RATs) are software-based malware that give hackers complete control over an infected system. While they typically need to be installed through phishing emails or malicious downloads, the installation can often happen through physical devices as well, such as a USB drive. Once a RAT is deployed, hackers can access everything on a computer—files, browsing history, passwords, and even live webcam and microphone feeds. This level of access makes RATs one of the most potent tools for data theft.
A case that demonstrates the effectiveness of RATs comes from the 2014 cyber espionage attack on Sony Pictures. Hackers used a variant of a RAT to gain full access to the company’s internal network, eventually stealing sensitive emails, unreleased films, and employee data. The attack had wide-reaching consequences, both financially and reputationally, for Sony. For data scientists working in the realm of sensitive information, understanding the risks associated with RATs is critical, as these tools can be used to steal intellectual property or exfiltrate proprietary algorithms and data models.
5. Bluetooth Sniffers: Silent Eavesdroppers
Bluetooth sniffers are hacking devices used to intercept communications between Bluetooth-enabled devices, such as smartphones, laptops, and even medical equipment. These devices can be used to steal sensitive data, such as personal information, credit card details, and even passwords, by exploiting weak or poorly configured Bluetooth security protocols. Bluetooth sniffing is particularly dangerous in environments like offices, airports, and coffee shops, where many devices may be connected to public Bluetooth networks.
In 2018, researchers demonstrated how a Bluetooth sniffer could be used to steal data from the Bluetooth-enabled locks on hotel room doors. Hackers could listen in on the communication between the hotel’s Bluetooth systems and gain unauthorized access to the rooms. This incident highlights just how vulnerable Bluetooth connections can be, especially when not properly encrypted. For data scientists working on projects involving IoT or connected devices, Bluetooth sniffers represent a key risk to the integrity and privacy of the data being transmitted.
6. Evil Maid Attacks: Physical Access, Digital Consequences
Evil Maid attacks are a type of attack where the hacker gains physical access to a device (often a laptop) and installs malicious software or exploits vulnerabilities to compromise the system. This could happen in an office setting or a hotel room, where an attacker steals a brief opportunity to tamper with the device. Once the software is installed, it may give the attacker remote access to the device, making it possible for them to steal data, spy on communications, or even monitor the device’s user.
One well-known case of an Evil Maid attack was the 2016 breach of a United States-based cybersecurity expert’s laptop. The attacker gained physical access to the machine, installed malicious software, and later exfiltrated valuable intellectual property and classified data. The “Evil Maid” name stems from a scenario where an attacker, posing as a hotel maid, takes advantage of the brief period while the owner of the laptop is away. This attack underscores the importance of physical security when handling sensitive data, particularly when using portable devices.
7. SIM Card Cloning: Hijacking Communication Channels
SIM card cloning involves copying the unique identifiers of a mobile device’s SIM card, allowing hackers to intercept calls, messages, and data sent to and from the phone. This attack is particularly dangerous because it gives the attacker control over the victim’s communication, including the ability to bypass two-factor authentication (2FA) systems that rely on SMS. The attack can be carried out with simple, off-the-shelf equipment, and is commonly used in targeted attacks against individuals or organizations.
A high-profile example of SIM card cloning occurred in 2014, when hackers used the technique to hijack the mobile phones of high-profile targets, including journalists and politicians. This attack compromised the security of sensitive communications and even enabled hackers to impersonate victims in fraudulent transactions. For data scientists, SIM card cloning represents a risk, especially for mobile applications that store sensitive user data or rely on mobile authentication systems.
8. RFID Skimmers: Stealing Data from a Distance
Radio Frequency Identification (RFID) skimmers are devices used to intercept signals from RFID-enabled cards, such as credit cards, identification cards, and access control cards. These skimmers can read data from a distance without physical contact with the card, making them ideal for stealthily stealing information. RFID skimming is especially dangerous in public spaces, such as airports or shopping malls, where many people carry RFID-enabled devices.
In 2017, a group of hackers used RFID skimmers to steal millions of dollars from unsuspecting victims at a major European airport. The skimmers were able to collect data from passengers’ RFID-enabled credit and debit cards, which the attackers later used to make fraudulent transactions. As a data scientist, understanding the vulnerabilities of RFID technology and how easily it can be exploited is critical, especially when designing secure data storage and authentication systems.
الجانب المظلم للتكنولوجيا – 8 أجهزة اختراق يمكنها سرقة بياناتك

في عالم اليوم فائق الترابط، لم يعد الأمن السيبراني مجرد مصطلح رائج فحسب، بل أصبح ضرورة ملحة. وبصفتنا علماء بيانات، فإننا نتعامل مع معلومات حساسة بشكل يومي، سواء كانت بيانات مستخدمين، أو سجلات مالية، أو ملكية فكرية. غير أن شبح سرقة البيانات، الذي يتنامى تهديده باستمرار، يلوح في الأفق بقوة؛ إذ يعمل المخترقون بلا كلل على تطوير أساليبهم وأدواتهم للوصول غير المصرح به إلى المعلومات القيمة. وفي حين أن الهجمات السيبرانية المتطورة غالباً ما تتصدر عناوين الأخبار، إلا أن إحدى أكثر الطرق فعالية لسرقة البيانات تتم من خلال أجهزة الاختراق المادية. وتتميز هذه الأجهزة بالبساطة وسهولة الاستخدام، وفي كثير من الحالات، تكون غير قابلة للكشف تقريباً. في هذا المقال، نستكشف أخطر ثمانية أجهزة اختراق يجب على علماء البيانات أن يكونوا على دراية بها، مسلطين الضوء على آلية عملها والمخاطر الواقعية التي تشكلها
1. USB Rubber Ducky: متسلل صغير الحجم، عظيم التأثير
“USB Rubber Ducky” يُعد جهاز
واحداً من أكثر أدوات الاختراق شهرة وسوء سمعة بين تلك التي يستخدمها مجرمو الإنترنت، ورغم أنه يبدو للوهلة الأولى
محمول (فلاش ميموري) غير ضار “USB” وكأنه محرك أقراص
إلا أن هذا الجهاز في الواقع عبارة عن محاكي لوحة مفاتيح عالي التقنية، فعند توصيله بجهاز الكمبيوتر
سلوك لوحة المفاتيح “Rubber Ducky” يحاكي جهاز
مرسلاً سلسلة من ضغطات المفاتيح القادرة
للوصول غير المصرح به (Backdoors) على فتح أبواب خلفية
أو سرقة كلمات المرور، أو حتى تنفيذ تعليمات برمجية خبيثة على الجهاز المخترق، ورغم تصميمه البسيط نسبياً
في قدرته على تجاوز التدابير الأمنية “Rubber Ducky” تكمن فعالية جهاز
مثل جدران الحماية وبرامج مكافحة الفيروسات – وذلك من خلال استغلال الاتصال الموثوق به القائم بين لوحة المفاتيح وجهاز الكمبيوتر
ومن الأمثلة الواقعية على استخدام هذه الأداة ما حدث في الهجوم الشهير الذي وقع عام 2010 على إحدى القواعد العسكرية الأمريكية في منطقة الشرق الأوسط
“USB Rubber Ducky” حيث استخدم المخترقون جهاز
لاختراق الشبكة العسكرية وزرع برمجية خبيثة متطورة
والتي نجحت لاحقاً في تخريب البرنامج النووي الإيراني “Stuxnet” تُدعى
ورغم أن هذه الحادثة تضمنت استخدام برمجيات خبيثة بالغة التطور، إلا أنها توضح مدى السهولة التي يمكن بها للمهاجمين استخدام أجهزة صغيرة الحجم
“Rubber Ducky” مثل
للسيطرة على الأنظمة الحيوية. وبصفتنا علماء بيانات، ينبغي علينا أن ندرك أن هذه الأجهزة قد تُستخدم أيضاً داخل بيئات العمل المؤسسية لسرقة البيانات الحساسة واستخراجها خلسةً من أجهزة الكمبيوتر الخاصة بالشركات
2. الأداة المثالية لهجمات الرجل في المنتصف :Wi-Fi Pineapple
أداةً صُممت في الأصل لأغراض اختبار الاختراق Wi-Fi Pineapple تُعد أداة
إلا أنها شقت طريقها لتستقر في أيدي القراصنة ذوي النوايا الخبيثة
Wi-Fi وهي في جوهرها جهاز محمول يقوم بإنشاء شبكات
وهمية (أو مارقة) يتصل بها المستخدمون غير المرتابين، ظناً منهم أنها نقاط اتصال شرعية وآمنة. وبمجرد إتمام الاتصال، يتمكن القراصنة من مراقبة كافة البيانات المُرسلة بين المستخدم والشبكة، بل والتلاعب بها أيضاً؛ مما يجعلها أداةً بالغة القوة
(MITM) لتنفيذ هجمات “الرجل في المنتصف
اعتراض بيانات تسجيل الدخول Wi-Fi Pineapple وتستطيع أداة
والمعلومات المصرفية، وأي بيانات حساسة أخرى يجري تداولها عبر الشبكة
سيئ السمعة DigiNotar ويُبرز حادث “اختراق
2011 الذي وقع في عام
مدى الخطورة الكامنة في هجمات “الرجل في المنتصف”، ففي ذلك الحادث، استغل القراصنة هيئة إصدار شهادات رقمية تم اختراقها
حيث قاموا بإعادة توجيه المستخدمين MITM لتنفيذ سلسلة من هجمات
(Phishing) نحو مواقع إلكترونية احتيالية
عملت على جمع بيانات تسجيل الدخول الخاصة بهم
Wi-Fi Pineapple وفي سياق الهجوم باستخدام أداة
يمكن للقراصنة شن هجوم مماثل بكل سهولة، لا سيما في الأماكن العامة مثل المقاهي، والمطارات، والفنادق؛ حيث يزداد احتمال اتصال المستخدمين بشبكات غير موثوقة، وبالنسبة لعلماء البيانات الذين يتعاملون مع البيانات المخزنة سحابياً
(IoT) أو تلك المرتبطة بـ “إنترنت الأشياء”
تهديداً جسيماً لسلامة البيانات وموثوقيتها Wi-Fi Pineapple تُمثل أداة
3. : خفية ومستمرة (Keyloggers) أجهزة تسجيل ضربات المفاتيح
(Keyloggers) تُعد أجهزة تسجيل ضربات المفاتيح
من أكثر أدوات الاختراق مكراً وخبثاً المتاحة حالياً
USB صُممت هذه الأجهزة – التي غالباً ما تكون بحجم وحدة تخزين
صغيرة أو لوحة دوائر إلكترونية – لتسجيل كل ضربة مفتاح يتم إجراؤها على جهاز الكمبيوتر أو الهاتف المحمول بصمت ودون أن يلحظها أحد، ويمكن بعد ذلك نقل البيانات التي تم جمعها إلى المخترق، وغالباً ما يتم ذلك دون علم الضحية. ويمكن تثبيت أجهزة تسجيل ضربات المفاتيح على الأجهزة العامة، أو محطات عمل الموظفين، أو حتى الهواتف الذكية؛ سواء كان ذلك عبر تطبيقات خبيثة أو من خلال الوصول المادي المباشر للجهاز
ومن الأمثلة السيئة السمعة على ذلك ما حدث في عام 2005، حين استخدم مجرمو الإنترنت مزيجاً من أجهزة وبرمجيات تسجيل ضربات المفاتيح لسرقة ملايين الدولارات من الحسابات المصرفية لضحايا لم يساورهم أي شك. وقد تمكن المخترقون من مراقبة ضربات المفاتيح، والتقاط أسماء المستخدمين، وكلمات المرور، والتفاصيل المصرفية، وصولاً في النهاية إلى الدخول المباشر إلى الحسابات. وبصفتنا علماء بيانات، فإننا غالباً ما نعتمد على أمن الأجهزة التي نعمل عليها لحماية البيانات الحساسة؛ غير أن واقع هجمات تسجيل ضربات المفاتيح يذكرنا بمدى السهولة التي يمكن بها تعريض المعلومات للخطر من خلال أجهزة مادية بسيطة
سيطرة وسرقة بيانات كاملة : (RATs) ٤. برامج التجسس عن بُعد
(RATs) برامج التجسس عن بُعد
هي برامج خبيثة تمنح المخترقين سيطرة كاملة على النظام المصاب، على الرغم من أن تثبيتها يتم عادةً عبر رسائل البريد الإلكتروني التصيدية أو التنزيلات الخبيثة، إلا أنه يمكن تثبيتها أيضًا عبر أجهزة مادية
USB مثل ذاكرة
فبمجرد تثبيت برنامج التجسس عن بُعد، يستطيع المخترقون الوصول إلى كل شيء على جهاز الكمبيوتر – الملفات، وسجل التصفح، وكلمات المرور، وحتى البث المباشر من كاميرا الويب والميكروفون. هذا المستوى من الوصول يجعل برامج التجسس عن بُعد من أقوى أدوات سرقة البيانات
من الأمثلة التي تُظهر فعالية برامج التجسس عن بُعد، هجوم التجسس الإلكتروني الذي استهدف شركة سوني بيكتشرز عام ٢٠١٤، استخدم المخترقون نوعاً مختلفاً من برامج التجسس عن بُعد للوصول الكامل إلى الشبكة الداخلية للشركة، وتمكنوا في النهاية من سرقة رسائل بريد إلكتروني حساسة، وأفلام لم تُعرض بعد، وبيانات الموظفين، كان للهجوم عواقب وخيمة على سوني، سواءً من الناحية المالية أو من حيث السمعة، بالنسبة لعلماء البيانات العاملين في مجال المعلومات الحساسة، يُعدّ فهم المخاطر المرتبطة بتقنيات الوصول عن بُعد أمراً بالغ الأهمية، إذ يُمكن استخدام هذه الأدوات لسرقة الملكية الفكرية أو استخراج الخوارزميات ونماذج البيانات الخاصة
5. أجهزة التجسس عبر البلوتوث: أجهزة تنصت صامتة
أجهزة التجسس عبر البلوتوث هي أجهزة اختراق تُستخدم لاعتراض الاتصالات بين الأجهزة التي تدعم تقنية البلوتوث، مثل الهواتف الذكية وأجهزة الكمبيوتر المحمولة وحتى المعدات الطبية. يُمكن استخدام هذه الأجهزة لسرقة البيانات الحساسة، مثل المعلومات الشخصية وتفاصيل بطاقات الائتمان وحتى كلمات المرور، من خلال استغلال بروتوكولات أمان البلوتوث الضعيفة أو غير المُهيأة بشكل صحيح. يُعدّ التجسس عبر البلوتوث خطيراً بشكل خاص في بيئات مثل المكاتب والمطارات والمقاهي، حيث قد تكون العديد من الأجهزة متصلة بشبكات بلوتوث عامة في عام 2018، أظهر باحثون كيف يُمكن استخدام جهاز تجسس عبر البلوتوث لسرقة البيانات من أقفال أبواب غرف الفنادق التي تدعم تقنية البلوتوث. إذ يُمكن للمخترقين التنصت على الاتصالات بين أنظمة البلوتوث في الفندق والوصول غير المصرح به إلى الغرف. تُبرز هذه الحادثة مدى هشاشة اتصالات البلوتوث، خاصةً عند عدم تشفيرها بشكل صحيح. بالنسبة لعلماء البيانات العاملين على مشاريع تتعلق بإنترنت الأشياء أو الأجهزة المتصلة، تُمثل برامج التجسس على البلوتوث خطراً كبيراً على سلامة البيانات المنقولة وخصوصيتها
6. (Evil Maid) :هجمات “الخادمة الشريرة”
تُعد هجمات “الخادمة الشريرة” نوعاً من الهجمات التي يتمكن فيها المخترق من الوصول مادياً إلى جهازٍ ما (غالباً ما يكون جهاز كمبيوتر محمول)، ليقوم بعد ذلك بتثبيت برمجيات خبيثة أو استغلال الثغرات الأمنية بهدف اختراق النظام. وقد يحدث هذا النوع من الهجمات في بيئة العمل المكتبية أو داخل غرف الفنادق، حيث ينتهز المهاجم فرصة وجيزة للتلاعب بالجهاز. وبمجرد تثبيت البرمجيات الخبيثة، قد تمنح المهاجم إمكانية الوصول عن بُعد إلى الجهاز، مما يتيح له سرقة البيانات، أو التجسس على الاتصالات، أو حتى مراقبة تحركات مستخدم الجهاز
ومن أبرز الأمثلة المعروفة على هجمات “الخادمة الشريرة” حادثة الاختراق التي وقعت في عام 2016، واستهدفت جهاز الكمبيوتر المحمول الخاص بخبير في الأمن السيبراني مقيم في الولايات المتحدة. إذ تمكن المهاجم من الوصول مادياً إلى الجهاز، وقام بتثبيت برمجيات خبيثة، ومن ثم نجح لاحقاً في استخراج ملكية فكرية قيّمة وبيانات مصنفة على أنها سرية. ويستمد اسم “الخادمة الشريرة” أصله من سيناريو يقوم فيه المهاجم – متظاهراً بأنه خادمة في فندق – باستغلال الفترة الوجيزة التي يغيب فيها مالك الجهاز المحمول عن المكان. ويُبرز هذا الهجوم مدى أهمية الأمن المادي عند التعامل مع البيانات الحساسة، لا سيما عند استخدام الأجهزة المحمولة
7. اختطاف قنوات الاتصال : SIM استنساخ بطاقات
SIM تتضمن عملية استنساخ بطاقات
نسخ المعرفات الفريدة الخاصة ببطاقة الاتصال الموجودة في جهاز الهاتف المحمول، مما يتيح للمخترقين اعتراض المكالمات والرسائل والبيانات الصادرة من الهاتف أو الواردة إليه، ويُعد هذا الهجوم خطيراً للغاية؛ لأنه يمنح المهاجم سيطرة كاملة على اتصالات الضحية، بما في ذلك القدرة
(2FA) على تجاوز أنظمة المصادقة الثنائية
SMS التي تعتمد في عملها على الرسائل النصية القصيرة
ويمكن تنفيذ هذا الهجوم باستخدام معدات بسيطة ومتاحة تجارياً، وغالباً ما يُستخدم في الهجمات الموجهة ضد أفراد بعينهم أو مؤسسات محددة.
SIM ومن الأمثلة البارزة على حوادث استنساخ بطاقات
ما حدث في عام 2014، حين استخدم مخترقون هذه التقنية لاختطاف الهواتف المحمولة الخاصة بشخصيات بارزة، بمن فيهم صحفيون وسياسيون. وقد أدى هذا الهجوم إلى تعريض أمن الاتصالات الحساسة للخطر، بل ومكّن المخترقين من انتحال شخصيات الضحايا لتنفيذ معاملات احتيالية. وبالنسبة لعلماء البيانات
خطراً حقيقياً SIM يمثل استنساخ بطاقات
لا سيما فيما يتعلق بتطبيقات الهاتف المحمول التي تقوم بتخزين بيانات المستخدمين الحساسة، أو تلك التي تعتمد على أنظمة المصادقة عبر الهاتف المحمول
8. سرقة البيانات عن بُعد : RFID أجهزة قشط بيانات
RFID Skimmers تُعرف أجهزة قشط بيانات تحديد الهوية بموجات الراديو
بأنها أجهزة تُستخدم لاعتراض الإشارات الصادرة عن البطاقات
RFID التي تدعم تقنية
مثل بطاقات الائتمان، وبطاقات الهوية الشخصية، وبطاقات التحكم في الدخول. بإمكان أجهزة القشط هذه قراءة البيانات عن بُعد دون الحاجة إلى أي اتصال مادي بالبطاقة، مما يجعلها أداة مثالية لسرقة المعلومات خلسةً
RFID ويُعد قشط بيانات تقنية تحديد الهوية بموجات الراديو
خطيراً للغاية في الأماكن العامة، مثل المطارات أو مراكز التسوق، حيث يحمل الكثير من الأشخاص أجهزة تدعم هذه التقنية
وفي عام 2017
RFID استخدمت مجموعة من المتسللين أجهزة قشط
لسرقة ملايين الدولارات من ضحايا غير مدركين للخطر في أحد المطارات الأوروبية الكبرى؛ إذ تمكنت تلك الأجهزة من جمع البيانات من بطاقات الائتمان والخصم الخاصة بالمسافرين
RFID والمزودة بتقنية
وهي البيانات التي استغلها المهاجمون لاحقاً لتنفيذ معاملات احتيالية، وبصفتي عالماً في مجال البيانات
RFID فإن إدراك نقاط الضعف الكامنة في تقنية
ومدى سهولة استغلالها يُعد أمراً بالغ الأهمية، لا سيما عند تصميم أنظمة آمنة لتخزين البيانات والمصادقة عليها

































































































































































































































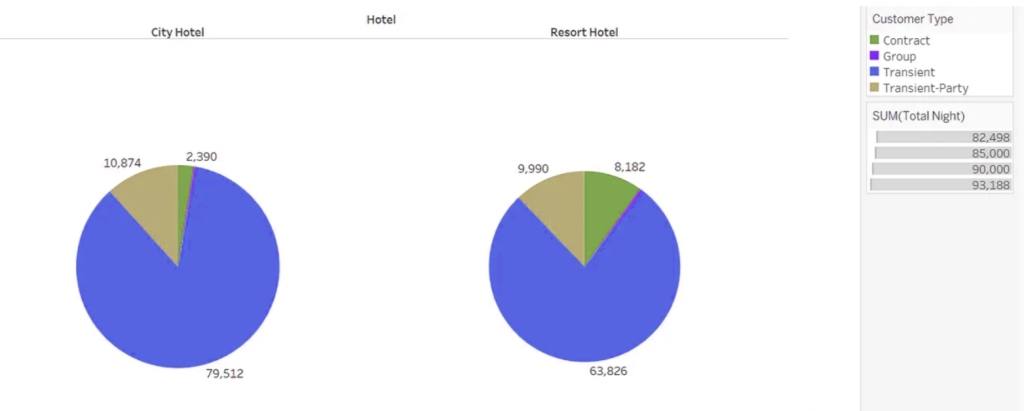
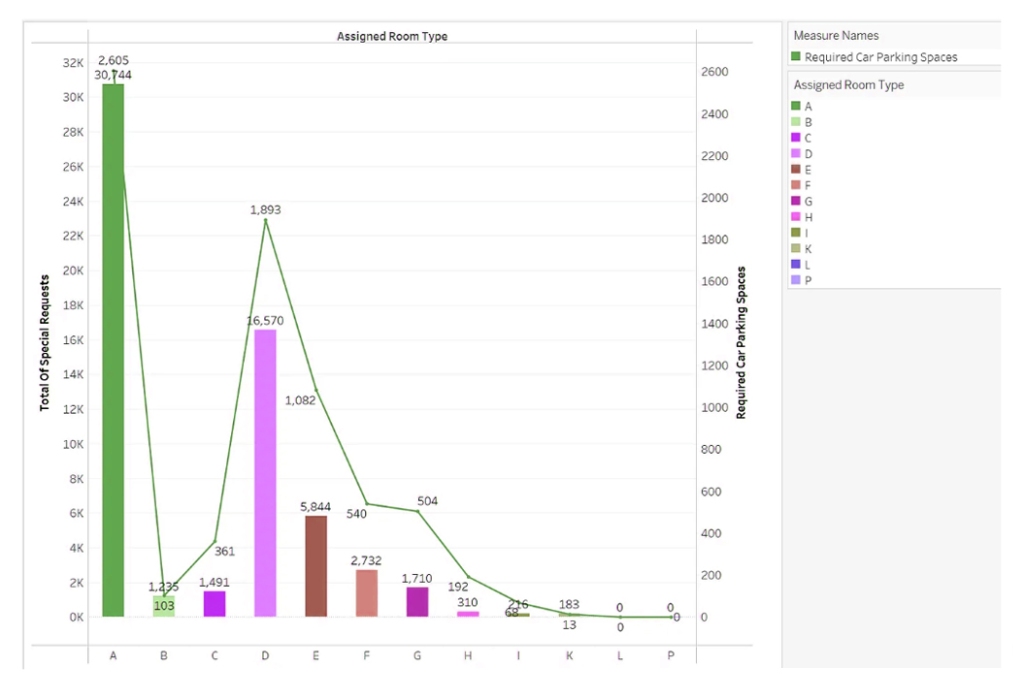
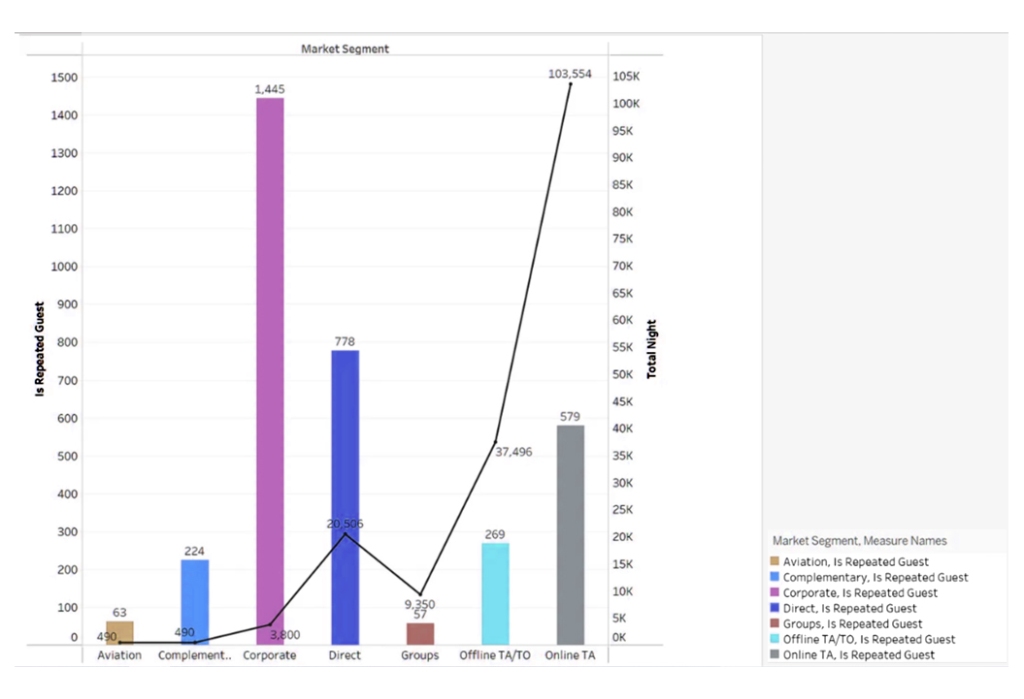
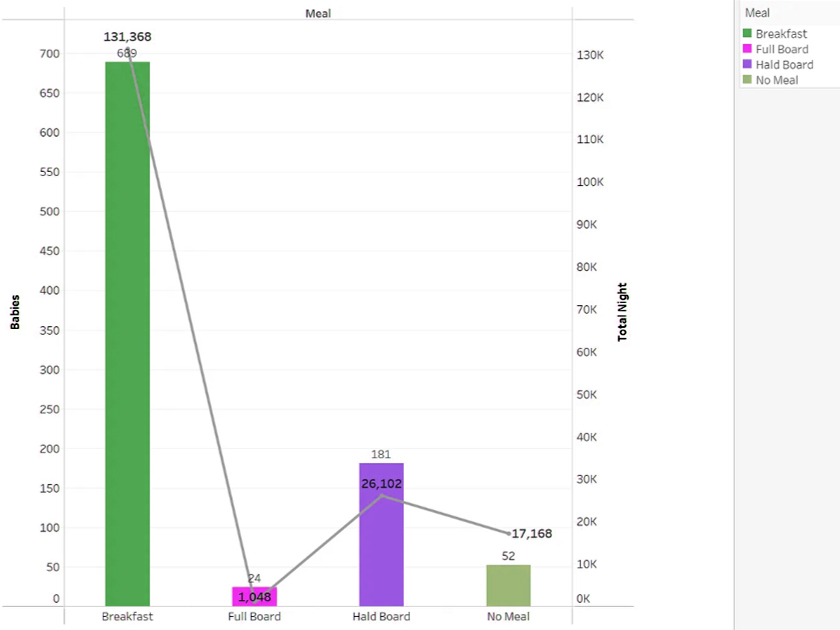






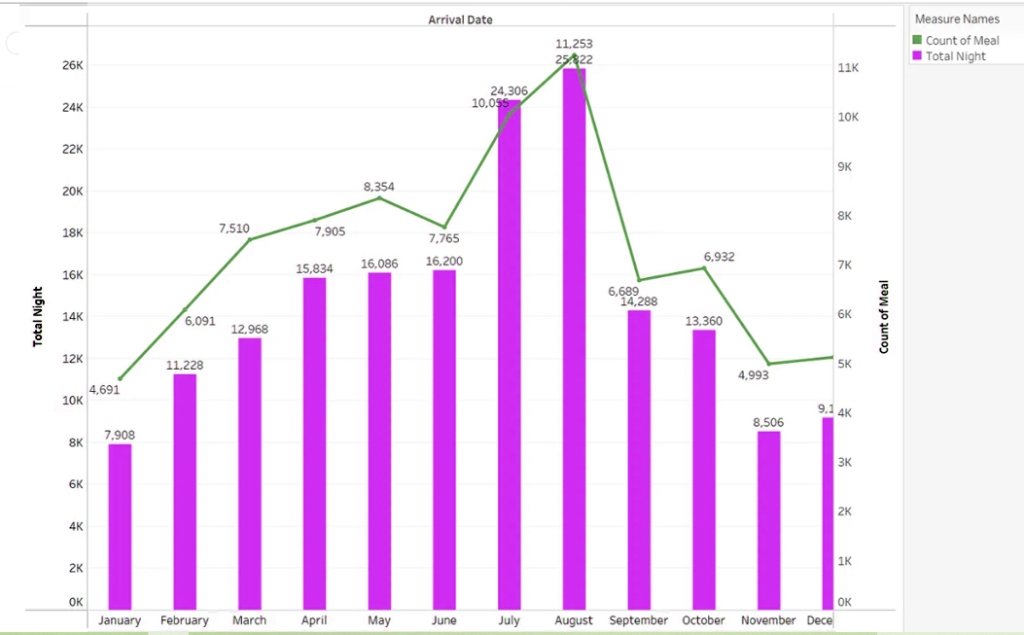
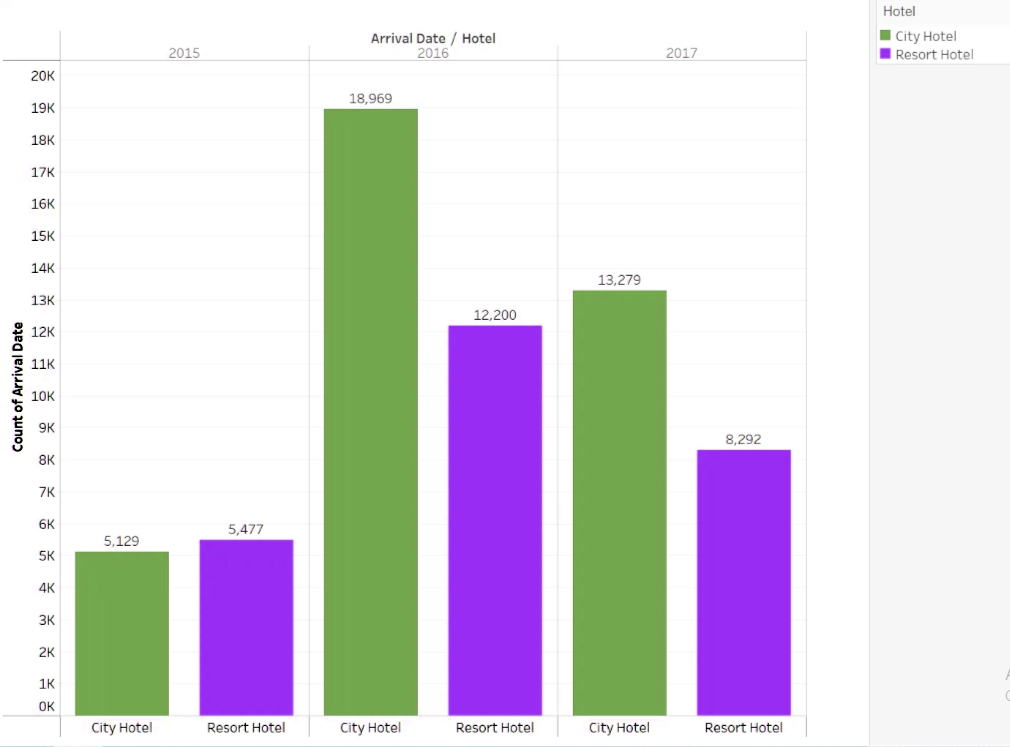
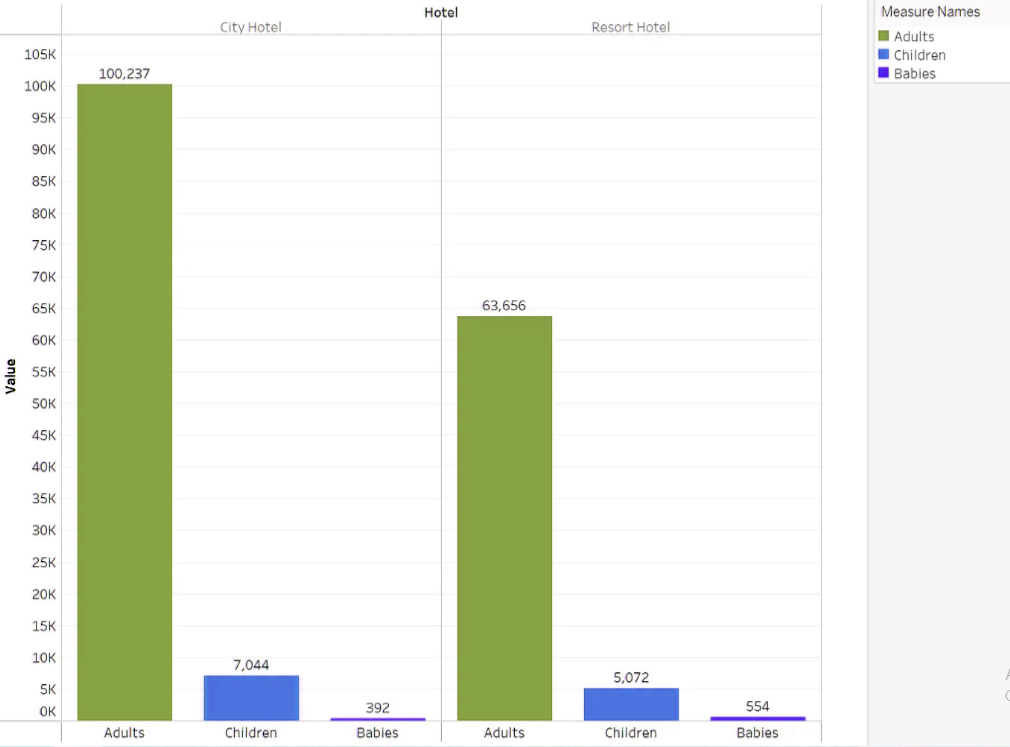
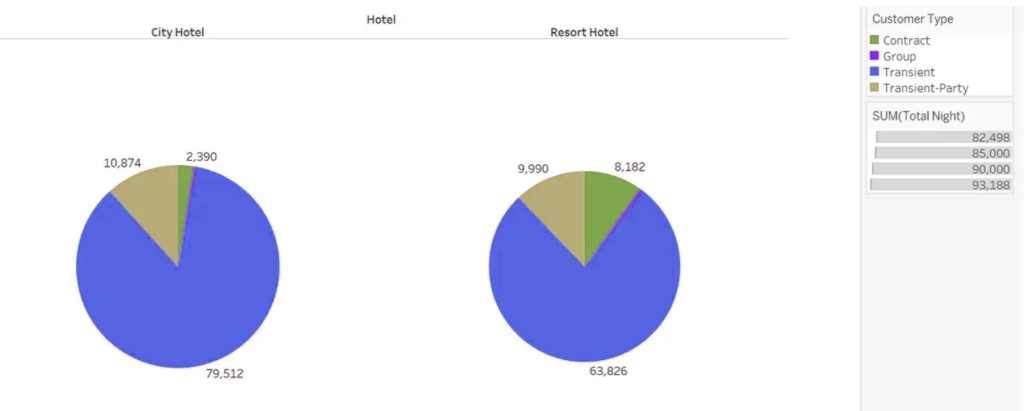
















































































































































































































































































You must be logged in to post a comment.